
キューブの作成
キューブとそれのレポートへの表示という部分は、まさにビジネスインテリジェンスのキモです。
キューブって何?という人は、「ビジネスインテリジェンスで使われる『キューブ』とは?」をみておいてください。
ここでは、「データソースとデータセットの作成」「データセットへの計算カラムの追加」で作成した、 データセットからキューブを作成します。
クロスタブのためのキューブの作成
キューブを作るには Data Explorer の Data Cubes を右クリックして、"New Data Cube" を選択します。
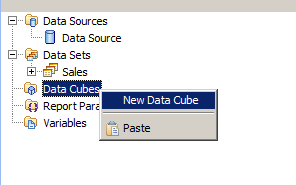
するとデータキューブビルダーが起動します。
データセットは先に作成しておいた "Sales" データセットを選び、データキューブの名前は "SalesCube" にしておきましょう。
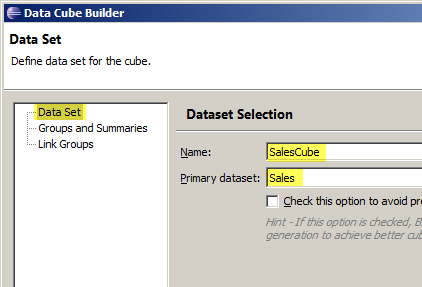
次にディメンションとメジャーを定義します。(ディメンション、メジャーという言葉の意味については「ビジネスインテリジェンスで使われる『キューブ』とは?」をみてください)
BIRT のデータキューブビルダーではディメンションは「グループ」、メジャーは「サマリーフィールド」とも呼ばれています。
ディメンションの定義
今回はディメンションは「日付」と「従業員」という二つのディメンションとなります。そこでそれらを表すキー、OrderDate と EmployeeID をディメンションとして定義します。
まず左側のツリーから "Groups and Summaries" を選択します。
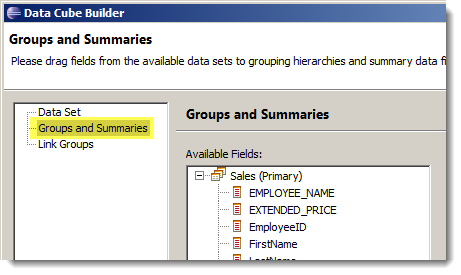
グループ (ディメンション) を作成するには、データセット内のフィールドをドラックしてきて、"Drop a field here to create a group" (グループを作成するにはフィールドをここにドロップ) と描いてあるところにドロップします。
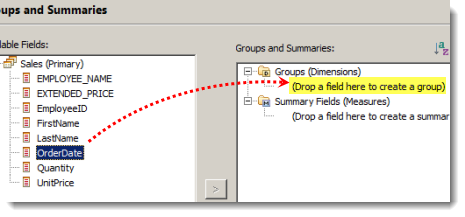
するとグループレベルを問うポップアップが表示されますが、ここでは "Regular Group" を選択します。
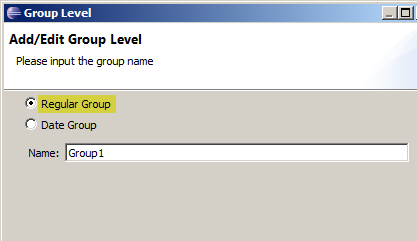
これで OrderDate を要素に持つディメンションが定義できました。
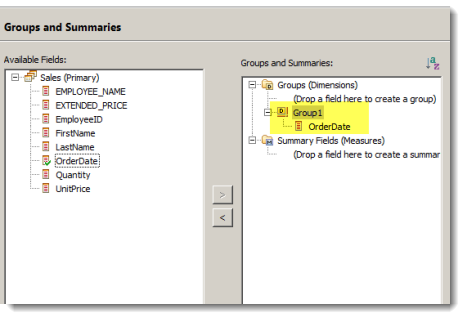
同様に「従業員」を表す EmployeeID フィールドを用いてもうひとつディメンションを作成します。
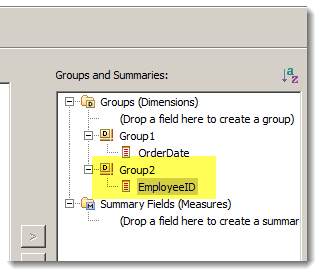
さらにここでは "従業員名" でデータ分析を行いたいので、Group2 の中に名前 (EXTENDED_NAME) を追加しておきます。
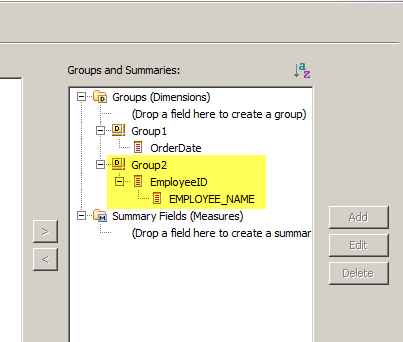
キー以外の情報を使うと、データが重複したときに正しくないレポートが作られることになるので気をつけてください。例えばここで、名前でレポート表示したいからといって、 名前のみをディメンションに設定してしまうと、同姓同名の従業員がいた場合、それらの人たちのデータが集計されてしまいます。こうした問題を避けるため、キーとなるフィールドをグループに含めてください。
メジャーの定義
次にメジャーを定義します。BIRT レポートではサマリーフィールドとも呼ばれています。
メジャーの定義も、ディメンションの定義と同様に、データセットのフィールドを所定の場所にドロップすれば OK です。
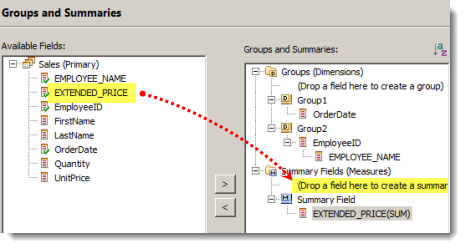
以上でキューブの作成及びメジャーとディメンションの定義が完了しました。
データエクスプローラでみると、確かにキューブが作成されていますね。
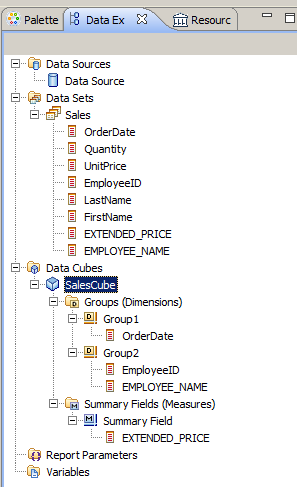
以上でキューブが作成され、クロスタブレポートを作る準備ができました。
次に実際にキューブとクロスタブコンポーネントをバインドし、クロスタブレポートの作成を行います。